









Nedávno sme diskutovali o použití funkcie FILTER.XML na import údajov XML z internetu – hlavnej úlohe, na ktorú je táto funkcia v skutočnosti určená. Po ceste však vyplávalo na povrch ďalšie nečakané a krásne využitie tejto funkcie – na rýchle rozdelenie lepkavého textu do buniek.
Povedzme, že máme takýto stĺpec údajov:

Samozrejme, pre pohodlie by som to chcel rozdeliť do samostatných stĺpcov: názov spoločnosti, mesto, ulica, dom. Môžete to urobiť niekoľkými rôznymi spôsobmi:
- Použitie Text po stĺpcoch z karty dátum (Údaje – text do stĺpcov) a urobte tri kroky Analyzátor textu. Ak sa však údaje zajtra zmenia, budete musieť celý proces zopakovať znova.
- Načítajte tieto údaje do Power Query a rozdeľte ich tam a potom ich nahrajte späť do hárka a potom aktualizujte dotaz, keď sa údaje zmenia (čo je už jednoduchšie).
- Ak potrebujete aktualizovať za chodu, môžete napísať niekoľko veľmi zložitých vzorcov, aby ste našli čiarky a extrahovali text medzi nimi.
A môžete to urobiť aj elegantnejšie a použiť funkciu FILTER.XML, ale čo to má spoločné?
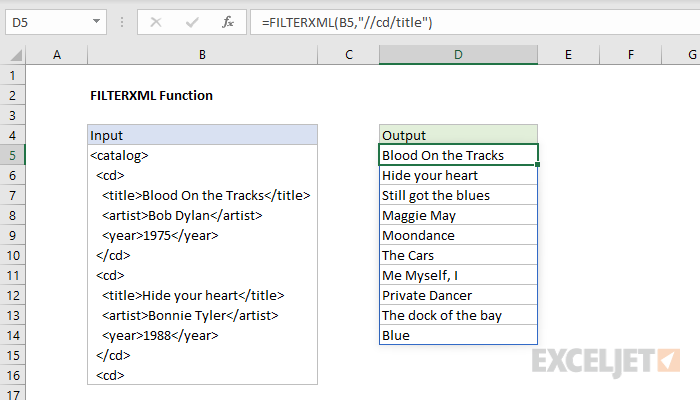
Funkcia FILTER.XML prijíma ako svoj počiatočný argument kód XML – text označený špeciálnymi značkami a atribútmi, a potom ho analyzuje do svojich komponentov, pričom extrahuje fragmenty údajov, ktoré potrebujeme. Kód XML zvyčajne vyzerá takto:

V XML musí byť každý dátový prvok uzavretý v značkách. Značka je nejaký text (v príklade vyššie je to manažér, meno, zisk) uzavretý v lomených zátvorkách. Štítky sú vždy v pároch – otváranie a zatváranie (s lomkou na začiatku).
Funkcia FILTER.XML dokáže jednoducho extrahovať obsah všetkých tagov, ktoré potrebujeme, napríklad mená všetkých manažérov, a (hlavne) zobraziť všetky naraz v jednom zozname. Našou úlohou je teda pridať tagy do zdrojového textu a previesť ho na XML kód vhodný pre následnú analýzu pomocou funkcie FILTER.XML.
Ak vezmeme prvú adresu z nášho zoznamu ako príklad, potom ju budeme musieť zmeniť na túto konštrukciu:

Zavolal som globálne otváranie a zatváranie všetkých textových značiek ta značky rámujúce každý prvok sú s., ale môžete použiť akékoľvek iné označenie – na tom nezáleží.
Ak z tohto kódu odstránime zarážky a zlomy riadkov – mimochodom úplne, voliteľné a pridané len kvôli prehľadnosti, všetko sa zmení na riadok:
![]()
A dá sa už pomerne jednoducho získať zo zdrojovej adresy tak, že v nej čiarky nahradíme pár tagmi pomocou funkcie NÁHRADA (NÁHRADIE) a lepenie so symbolom & na začiatku a na konci úvodného a záverečného štítku:

Na rozšírenie výsledného rozsahu horizontálne použijeme štandardnú funkciu TRANSP (TRANSPOSE), pričom do nej zabalíme náš vzorec:

Dôležitou črtou celého tohto dizajnu je, že v novej verzii Office 2021 a Office 365 s podporou dynamických polí nie sú na zadávanie potrebné žiadne špeciálne gestá – stačí zadať a kliknúť na vstúpiť – samotný vzorec zaberá počet buniek, ktoré potrebuje a všetko funguje s treskom. V predchádzajúcich verziách, kde ešte neboli dynamické polia, budete musieť pred zadaním vzorca najskôr vybrať dostatočný počet prázdnych buniek (môžete s okrajom) a po vytvorení vzorca stlačiť klávesovú skratku ctrl+smena+vstúpiťzadajte ho ako vzorec poľa.
Podobný trik možno použiť pri oddeľovaní textu zlepeného do jednej bunky cez zalomenie riadku:

Jediný rozdiel oproti predchádzajúcemu príkladu je, že namiesto čiarky tu nahradíme neviditeľný znak zalomenia riadku Alt + Enter, ktorý je možné vo vzorci zadať pomocou funkcie CHAR kódom 10.
- Jemnosť práce so zlommi riadkov (Alt + Enter) v Exceli
- Rozdelenie textu podľa stĺpcov v Exceli
- Nahradenie textu textom SUBSTITUTE