









Predpokladajme, že máte zoznam, v ktorom sú s rôznym stupňom „jednoduchosti“ zapísané počiatočné údaje – napríklad adresy alebo názvy spoločností:
 |  |
Je jasne vidieť, že to isté mesto alebo spoločnosť je tu prítomné v pestrých variantoch, čo samozrejme spôsobí veľa problémov pri práci s týmito tabuľkami v budúcnosti. A ak sa trochu zamyslíte, nájdete množstvo príkladov podobných úloh z iných oblastí.
Teraz si predstavte, že takéto skreslené údaje k vám chodia pravidelne, teda nejde o jednorazový príbeh „ručne opravte, zabudnite“, ale o problém pravidelne a vo veľkom počte buniek.
Čo robiť? Nenahrádzajte ručne krivý text 100500 XNUMX-krát správnym textom pomocou poľa „Nájsť a nahradiť“ alebo kliknutím na ctrl+H?
Prvá vec, ktorá vám v takejto situácii príde na myseľ, je vykonať hromadnú výmenu podľa vopred zostavenej referenčnej knihy párovania nesprávnych a správnych možností – takto:

Bohužiaľ, so zjavnou prevahou takejto úlohy, Microsoft Excel nemá jednoduché vstavané metódy na jej riešenie. Na začiatok poďme zistiť, ako to urobiť pomocou vzorcov bez zapojenia „ťažkého delostrelectva“ vo forme makier vo VBA alebo Power Query.
Prípad 1. Hromadná úplná výmena
Začnime pomerne jednoduchým prípadom – situáciou, kedy potrebujete nahradiť starý pokrivený text novým. plne.
Povedzme, že máme dve tabuľky:

V prvom – pôvodné pestré názvy firiem. V druhom - referenčná kniha korešpondencie. Ak nájdeme v názve spoločnosti v prvej tabuľke ľubovoľné slovo zo stĺpca Nájsť, potom je potrebné tento pokrivený názov úplne nahradiť správnym – zo stĺpca náhradka druhá vyhľadávacia tabuľka.
Pre pohodlie:
- Obe tabuľky sú konvertované na dynamické („inteligentné“) pomocou klávesovej skratky ctrl+T alebo tím Vložiť – Tabuľka (Vložiť — Tabuľka).
- Na karte, ktorá sa zobrazí staviteľ (Dizajn) prvá tabuľka s názvom dátuma druhá referenčná tabuľka – Striedanie.
Aby sme vysvetlili logiku vzorca, poďme trochu z diaľky.
Ak vezmeme ako príklad prvú spoločnosť z bunky A2 a dočasne zabudneme na ostatné spoločnosti, skúsme určiť, ktorá možnosť zo stĺpca Nájsť sa tam stretáva. Ak to chcete urobiť, vyberte ľubovoľnú prázdnu bunku vo voľnej časti hárka a zadajte tam funkciu NÁJSŤ (NÁJSŤ):

Táto funkcia určuje, či je daný podreťazec zahrnutý (prvý argument sú všetky hodnoty zo stĺpca Nájsť) do zdrojového textu (prvá spoločnosť z tabuľky údajov) a mal by vypísať buď poradové číslo znaku, z ktorého bol text nájdený, alebo chybu, ak sa podreťazec nenašiel.
Trik je v tom, že keďže sme ako prvý argument zadali nie jednu, ale niekoľko hodnôt, táto funkcia tiež vráti nie jednu hodnotu, ale pole 3 prvkov. Ak nemáte najnovšiu verziu Office 365, ktorá podporuje dynamické polia, potom po zadaní tohto vzorca a kliknutí na vstúpiť toto pole uvidíte priamo na hárku:

Ak máte predchádzajúce verzie Excelu, potom po kliknutí na vstúpiť uvidíme len prvú hodnotu z výsledného poľa, teda chybu #HODNOTA! (#HODNOTA!).
Nemali by ste sa báť 🙂 Náš vzorec v skutočnosti funguje a stále môžete vidieť celé pole výsledkov, ak vyberiete zadanú funkciu v riadku vzorcov a stlačíte kláves F9(len nezabudnite stlačiť Escvrátiť sa k vzorcu):

Výsledné pole výsledkov znamená, že v pôvodnom pokrivenom názve spoločnosti (GK Morozko OAO) všetkých hodnôt v stĺpci Nájsť našiel len druhý (Morozko)a počnúc 4. znakom v rade.
Teraz do nášho vzorca pridáme funkciu ZOBRAZIŤ(VYHĽADAŤ):

Táto funkcia má tri argumenty:
- Požadovaná hodnota - môžete použiť akékoľvek dostatočne veľké číslo (hlavná vec je, že presahuje dĺžku akéhokoľvek textu v zdrojových údajoch)
- Zobrazený_vektor – rozsah alebo pole, kde hľadáme požadovanú hodnotu. Tu je predtým predstavená funkcia NÁJSŤ, ktorý vráti pole {#VALUE!:4:#VALUE!}
- vektor_výsledky – rozsah, z ktorého chceme vrátiť hodnotu, ak sa požadovaná hodnota nájde v zodpovedajúcej bunke. Tu sú správne mená zo stĺpca náhradka našu referenčnú tabuľku.
Hlavnou a nie samozrejmou vlastnosťou je tu funkcia ZOBRAZIŤ ak neexistuje presná zhoda, vždy hľadá najbližšiu najmenšiu (predchádzajúcu) hodnotu. Preto zadaním akéhokoľvek veľkého čísla (napríklad 9999) ako požadovanej hodnoty vynútime ZOBRAZIŤ nájdite bunku s najbližším najmenším číslom (4) v poli {#VALUE!:4:#VALUE!} a vráťte zodpovedajúcu hodnotu z vektora výsledku, teda správny názov firmy zo stĺpca náhradka.
Druhou nuansou je, že technicky je náš vzorec maticovým vzorcom, pretože funguje NÁJSŤ vráti ako výsledok nie jednu, ale pole troch hodnôt. Ale keďže funkcia ZOBRAZIŤ podporuje polia hneď po vybalení, potom tento vzorec nemusíme zadávať ako klasický vzorec poľa – pomocou klávesovej skratky ctrl+smena+vstúpiť. Postačí vám jednoduchý vstúpiť.
To je všetko. Dúfam, že pochopíš logiku.
Zostáva preniesť hotový vzorec do prvej bunky B2 stĺpca Opravená – a naša úloha je vyriešená!

Samozrejme, s obyčajnými (nie smart) tabuľkami tento vzorec tiež funguje skvele (len nezabudnite na kľúč F4 a oprava príslušných odkazov):

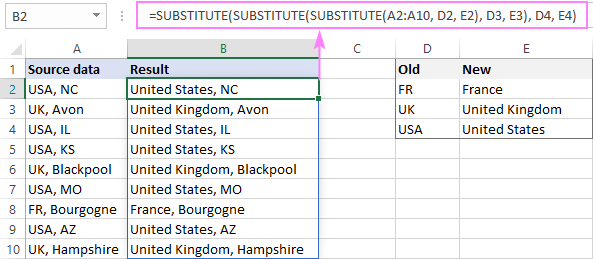
Prípad 2. Hromadná čiastočná výmena
Tento prípad je trochu zložitejší. Opäť tu máme dve „inteligentné“ tabuľky:

Prvá tabuľka s krivo napísanými adresami, ktorú treba opraviť (nazval som ju Údaje2). Druhá tabuľka je referenčná kniha, podľa ktorej musíte čiastočne nahradiť podreťazec v adrese (túto tabuľku som nazval Substitúcie2).
Zásadný rozdiel je v tom, že je potrebné nahradiť iba časť pôvodných údajov – napríklad prvá adresa je nesprávna „Sv. Petrohrad” na pravej strane „Sv. Petrohrad”, pričom zvyšok adresy (PSČ, ulica, dom) ponechajte tak, ako je.
Hotový vzorec bude vyzerať takto (pre ľahšie vnímanie som ho rozdelil na koľko riadkov pomocou ostatné+vstúpiť):

Hlavnú prácu tu vykonáva štandardná textová funkcia programu Excel NÁHRADA (NÁHRADIE), ktorý má 3 argumenty:
- Zdrojový text – prvá skreslená adresa zo stĺpca Adresa
- Čo hľadáme – tu použijeme trik s funkciou ZOBRAZIŤ (VYHĽADAŤ)z predchádzajúceho spôsobu vytiahnuť hodnotu zo stĺpca Nájsť, ktorý je zahrnutý ako fragment v zakrivenej adrese.
- Čím nahradiť – rovnakým spôsobom nájdeme v stĺpci zodpovedajúcu správnu hodnotu náhradka.
Zadajte tento vzorec pomocou ctrl+smena+vstúpiť ani tu nie je potrebný, hoci v skutočnosti ide o vzorec poľa.
A je jasne vidieť (pozri chyby #N/A na predchádzajúcom obrázku), že takýto vzorec má pri všetkej svojej elegancii niekoľko nevýhod:
- Funkcie SUBSTITUTE rozlišuje veľké a malé písmená, takže „Spb“ v predposlednom riadku sa v tabuľke náhrad nenašiel. Na vyriešenie tohto problému môžete použiť funkciu ZAMENIT (NAHRADIŤ), alebo predbežne prineste obe tabuľky do toho istého registra.
- Ak je text na začiatku správny alebo v ňom neexistuje žiadny fragment, ktorý by sa dal nahradiť (posledný riadok), potom náš vzorec vyvolá chybu. Tento moment je možné neutralizovať zachytením a nahradením chýb pomocou funkcie IFERROR (IFERROR):

- Ak pôvodný text obsahuje niekoľko fragmentov z adresára naraz, potom náš vzorec nahradí iba posledný (v 8. riadku, Ligovsky «Alej« zmenené na "pr-t", Ale "S-Pb" on „Sv. Petrohrad” už nie, pretože „S-Pb“ je v adresári vyššie). Tento problém možno vyriešiť opätovným spustením vlastného vzorca, ale už pozdĺž stĺpca Opravená:


Nie je to miestami dokonalé a ťažkopádne, ale oveľa lepšie ako rovnaká manuálna výmena, však? 🙂
PS
V ďalšom článku prídeme na to, ako implementovať takúto hromadnú náhradu pomocou makier a Power Query.
- Ako funguje funkcia SUBSTITUTE na nahradenie textu
- Hľadanie presnej zhody textu pomocou funkcie EXACT
- Vyhľadávanie a nahrádzanie s rozlišovaním malých a veľkých písmen (VLOOKUP s rozlišovaním malých a veľkých písmen)