









Formulácia problému
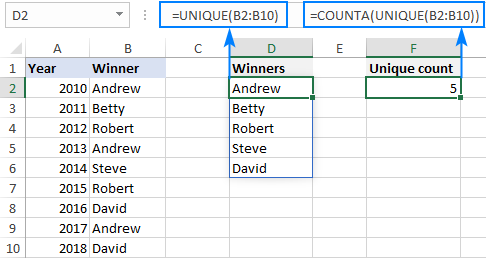
Existuje rozsah údajov, v ktorom sa niektoré hodnoty opakujú viac ako raz:

Úlohou je spočítať počet jedinečných (neopakujúcich sa) hodnôt v rozsahu. Vo vyššie uvedenom príklade je ľahké vidieť, že v skutočnosti sú uvedené iba štyri možnosti.
Zvážme niekoľko spôsobov, ako to vyriešiť.
Metóda 1. Ak nie sú žiadne prázdne bunky
Ak ste si istí, že v pôvodnom rozsahu údajov nie sú žiadne prázdne bunky, môžete použiť krátky a elegantný vzorec poľa:

Nezabudnite ho zadať ako maticový vzorec, teda po zadaní vzorca stlačte nie Enter, ale kombináciu Ctrl + Shift + Enter.
Technicky tento vzorec iteruje cez všetky bunky poľa a vypočíta pre každý prvok počet jeho výskytov v rozsahu pomocou funkcie COUNTIF (COUNTIF). Ak to predstavíme ako ďalší stĺpec, bude to vyzerať takto:

Potom sa vypočítajú zlomky 1/Počet výskytov pre každý prvok a všetky sú sčítané, čo nám dá počet jedinečných prvkov:

Metóda 2. Ak sú prázdne bunky
Ak sú v rozsahu prázdne bunky, budete musieť mierne vylepšiť vzorec pridaním kontroly prázdnych buniek (inak dostaneme chybu delenia 0 v zlomku):

To je všetko.
- Ako extrahovať jedinečné prvky z rozsahu a odstrániť duplikáty
- Ako zvýrazniť duplikáty v zozname farbou
- Ako porovnať dva rozsahy pre duplikáty
- Extrahujte jedinečné záznamy z tabuľky podľa daného stĺpca pomocou doplnku PLEX